Introduction to FPGA computing for the HPC ecosystem¶
Field Programmable Gate Array (FPGA)¶
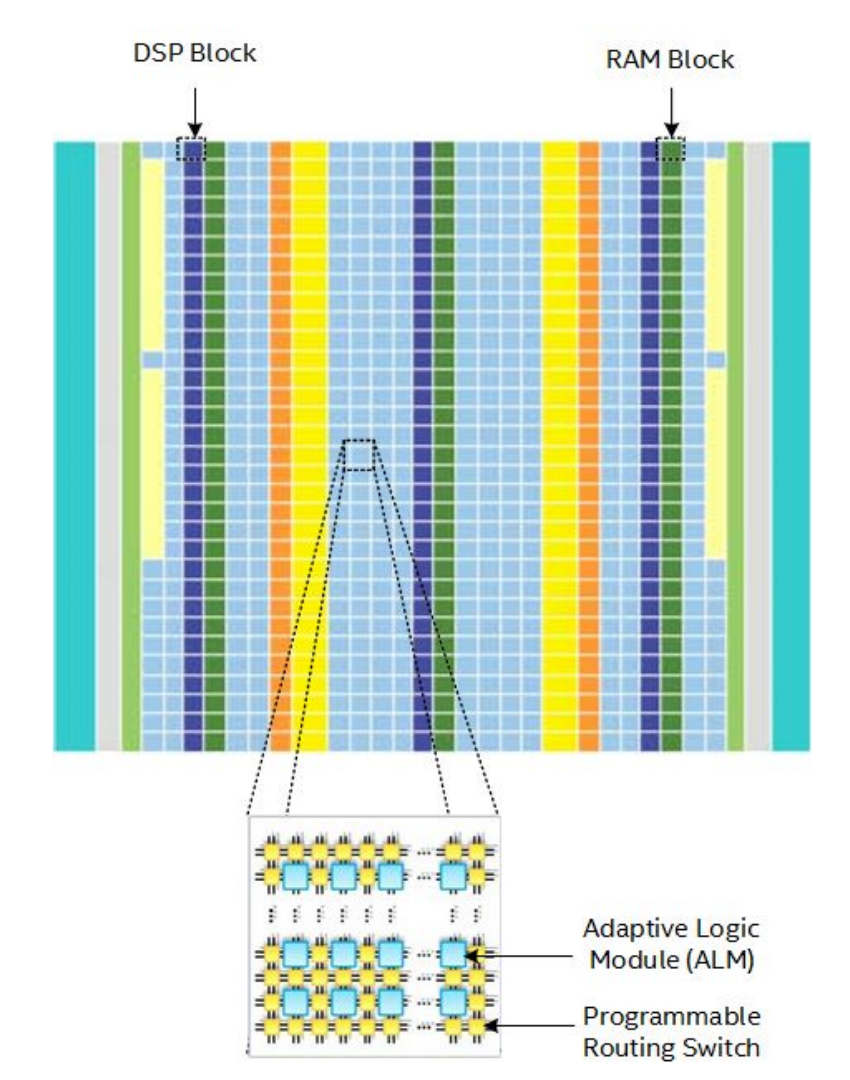 An FPGA (Field-Programmable Gate Array) is an integrated circuit designed to be configured by the user after manufacturing. It consists of an array of programmable logic blocks and a hierarchy of reconfigurable interconnects, allowing users to create custom digital circuits. FPGAs are known for their flexibility, enabling rapid prototyping and implementation of complex functions in hardware, making them suitable for applications in telecommunications, automotive, aerospace, and various other fields where custom and High-Performance Computing is needed.
An FPGA (Field-Programmable Gate Array) is an integrated circuit designed to be configured by the user after manufacturing. It consists of an array of programmable logic blocks and a hierarchy of reconfigurable interconnects, allowing users to create custom digital circuits. FPGAs are known for their flexibility, enabling rapid prototyping and implementation of complex functions in hardware, making them suitable for applications in telecommunications, automotive, aerospace, and various other fields where custom and High-Performance Computing is needed.
Applications¶

FPGA vendors¶
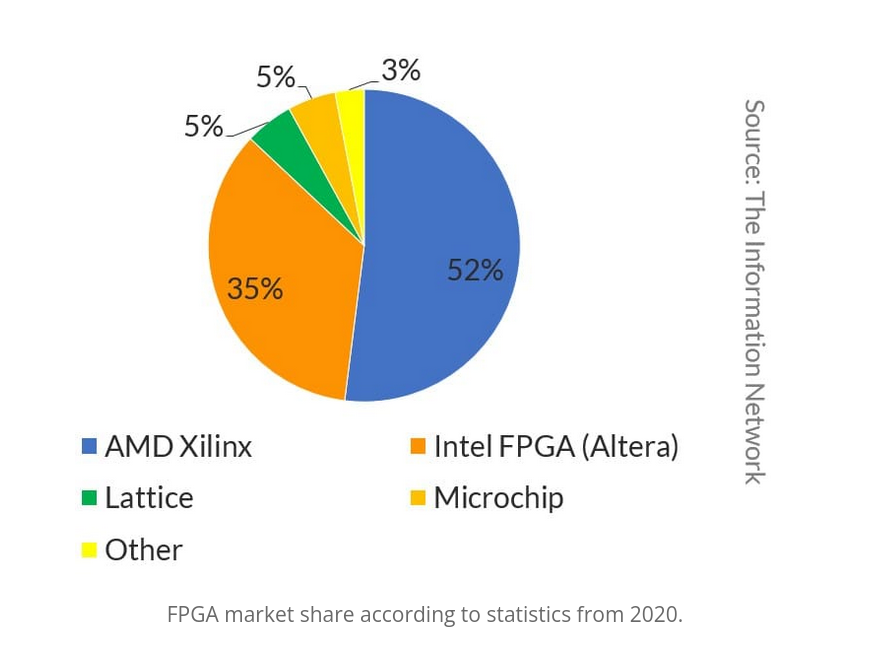
-
Two major FPGA vendors:
-
Intel acquired Altera in 2015
-
Xillinx is solely focusing on the FPGA market while Intel is a sum of many parts
-
Both profiles are very interesting for heterogeneous computing
-
Among the others:
- Lattice Semiconductor
- QuickLogic
- Microchip Technology
- Achronix
- Efinix
FPGA for the HPC ecosystem¶
FPGA Development Boards and HPC (High-Performance Computing) FPGA Cards serve different purposes and have distinct characteristics:
-
FPGA Development Boards are primarily designed for learning, prototyping, and small-scale projects. They typically feature user-friendly interfaces, a variety of I/O options, and often include additional components like sensors, buttons, and displays. These boards are intended for engineers, students, and hobbyists to develop and test FPGA-based designs.
-
HPC FPGA Cards, on the other hand, are specialized for High-Performance Computing tasks. These cards are optimized for integration into data centers and High-Performance Computing environments. They focus on maximizing computational power, energy efficiency, and data throughput. HPC FPGA cards are usually designed to be mounted in servers or workstations, and they often support advanced features like high-speed memory interfaces and network connectivity.
Difference Between FPGA Development Boards and HPC FPGA Cards
- Purpose: Primarily used for prototyping, learning, and development purposes.
- Design: These boards typically come with various interfaces (like HDMI, USB, Ethernet) and peripherals (like buttons, LEDs, and sensors) to facilitate easy testing and development.
- Flexibility: They offer a broad range of input/output options to support diverse projects and experiments.
- Cost: Generally more affordable than HPC FPGA cards due to their focus on versatility and accessibility.
- Target Audience: Suitable for students, hobbyists, and engineers working on initial project phases or small-scale applications.
- Specifications:
- Logic Cells: 33,280
- Block RAM: 1,800 Kbits
- External memory: None

- Purpose: Designed for High-Performance Computing (HPC) applications, focusing on accelerating compute-intensive tasks.
- Design: Typically more powerful, with higher logic capacity, memory, and bandwidth capabilities. They often come with specialized cooling solutions and are designed to be mounted in server racks.
- Performance: Optimized for tasks such as data center operations, machine learning, financial modeling, and large-scale scientific computations.
- Cost: Generally more expensive due to their advanced features and high-performance capabilities.
- Target Audience: Aimed at professionals in industries requiring significant computational power, such as data scientists, researchers, and engineers in High-Performance Computing sectors.
- Specifications:
- Logic Cells: 2,073,000
- Block RAM: 239.5 Mb
- External memory: 16GB HBM2

Parallelism model for FPGA¶
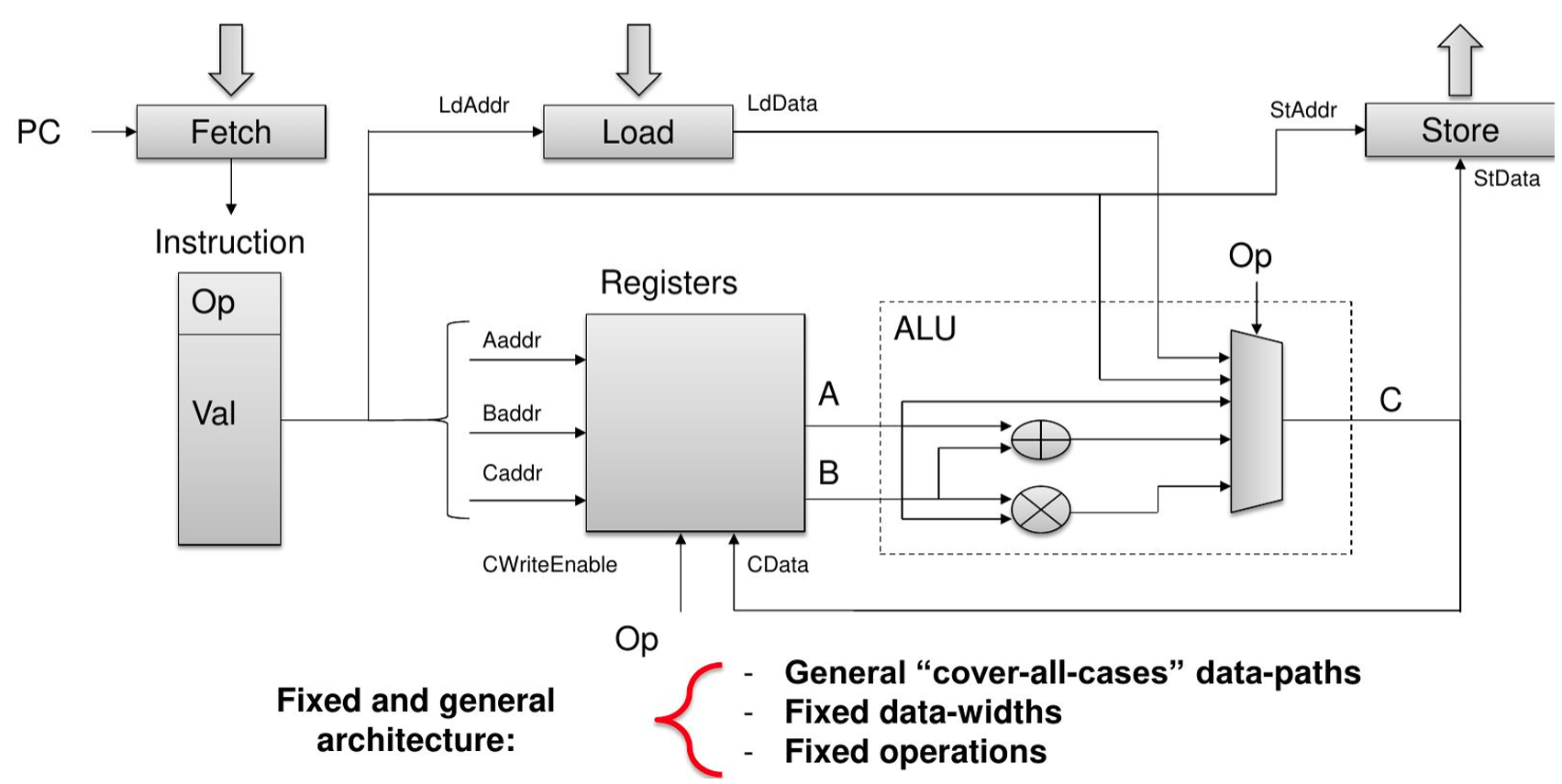
- The differences between Instruction Set Architecture (ISA) for CPUs and Spatial Architecture for FPGAs lie in how they process instructions and handle computation:
1. Instruction Set Architecture (ISA) for CPUs:¶
- Sequential Execution: CPUs operate using an Instruction Set Architecture (ISA), where a series of instructions (opcodes) are executed sequentially. The CPU fetches, decodes, and executes each instruction in a linear order.
- Control Flow Dominated: CPUs are designed for a wide range of tasks and rely on control flow (e.g., branches, loops) to manage the sequence of operations. They are optimized for tasks with complex control logic.
- Fixed Architecture: The CPU has a fixed architecture, with specific functional units like ALUs (Arithmetic Logic Units), registers, and cache memory. The same hardware is reused for different instructions.
- Pipelining and Caching: CPUs use techniques like pipelining (executing multiple instructions at different stages simultaneously) and caching (storing frequently accessed data) to improve performance.
2. Spatial Architecture for FPGAs:¶
- Parallel Execution: FPGAs use spatial architecture, where computation is distributed across a reconfigurable fabric of logic blocks and interconnects. Multiple operations can occur simultaneously in different parts of the FPGA.
- Data Flow Dominated: FPGAs are optimized for data flow processing, where data is passed through a pipeline of operations. This makes them ideal for tasks that benefit from parallelism, like signal processing or machine learning inference.
- Customizable Architecture: The architecture of an FPGA is not fixed; it can be customized by the user to implement specific hardware designs. This allows for the creation of custom data paths and processing units tailored to the task at hand.
- No Instruction Set: Unlike CPUs, FPGAs do not execute instructions in a traditional sense. Instead, they are programmed using hardware description languages (HDLs) like VHDL or Verilog to define how the hardware should behave.
In a nutshell:¶
- ISA for CPUs: Sequential, control-flow-oriented, with a fixed architecture using a predefined set of instructions. Suitable for general-purpose tasks.
- Spatial Architecture for FPGAs: Parallel, data-flow-oriented, with a customizable architecture that can be tailored for specific high-performance tasks. Suitable for specialized, parallelizable workloads.
Difference between Instruction Set architecture and Spatial architecture
- Made for general-purpose computation: hardware is constantly reused
- Workflow constrained by a set of pre-defined units (Control Units, ALUs, registers)
- Data/Register size are fixed
- Different instruction executed in each clock cycle : temporal execution
- Keep only what it needs -- the hardware can be reconfigured
- Specialize everything by unrolling the hardware: spatial execution
- Each operation uses a different hardware region
- The design can take more space than the FPGA offers

-
The most obvious source of parallelism for FPGA is pipelining by inserting registers to store each operation output and keep all hardware unit busy.
-
Pipelining parallelism has therefore many stages.
-
If you don't have enough work to fill the pipeline, then the efficiency is very low.
-
The authors of the DPC++ book have illustrated it perfectly in Chapter 17.
Pipelining example provided chap.17 (DPC++ book)
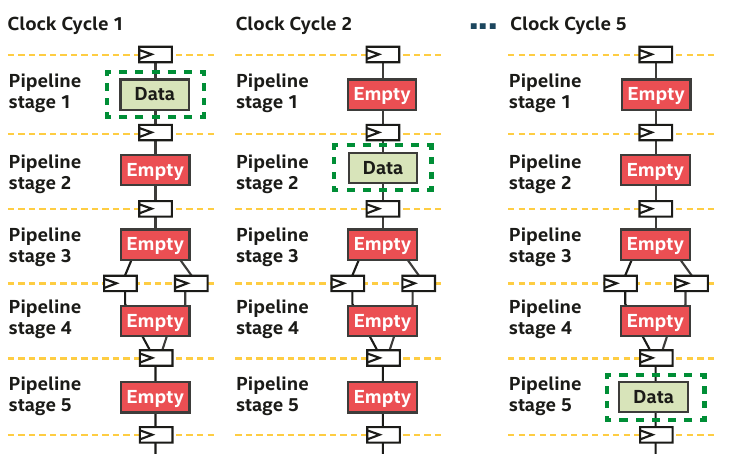
- The pipeline is mostly empty.
- Hardware units are not busy and the efficiency is thus low.
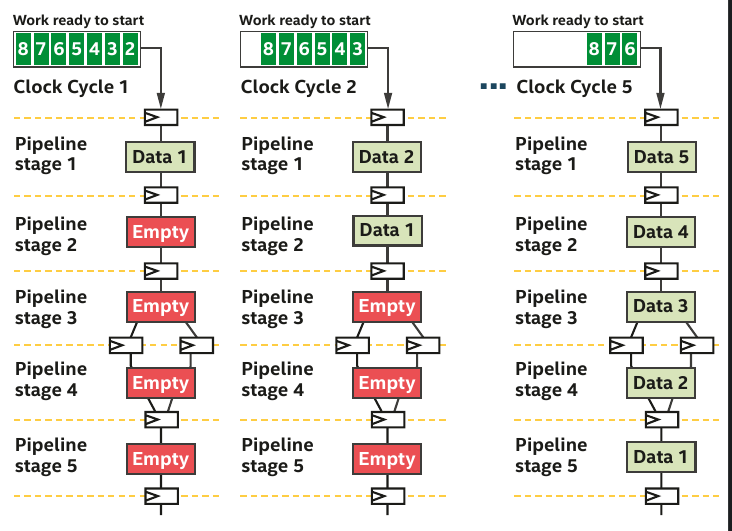
- More data than stages, the pipeline is full and all hardware units are busy.
Vectorization
Vectorization is not the main source of parallelism but help designing efficient pipeline. Since hardware can be reconfigured at will. The offline compiler can design N-bits Adders, multipliers which simplify greatly vectorization. In fact, the offline compiler vectorizes your design automatically if possible.
Pipelining with ND-range kernels¶
- ND-range kernels are based on a hierachical grouping of work-items
- A work-item represents a single unit of work
- Independent simple units of work don't communicate or share data very often
- Useful when porting a GPU kernel to FPGA
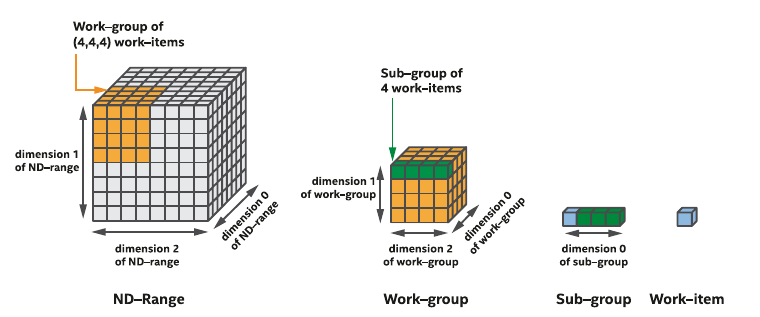
- FPGAs are different from GPU (lots of threads started at the same time)
- Impossible to replicate a hardware for a million of work-items
- Work-items are injected into the pipeline
- A deep pipeline means lots of work-items executing different tasks in parallel
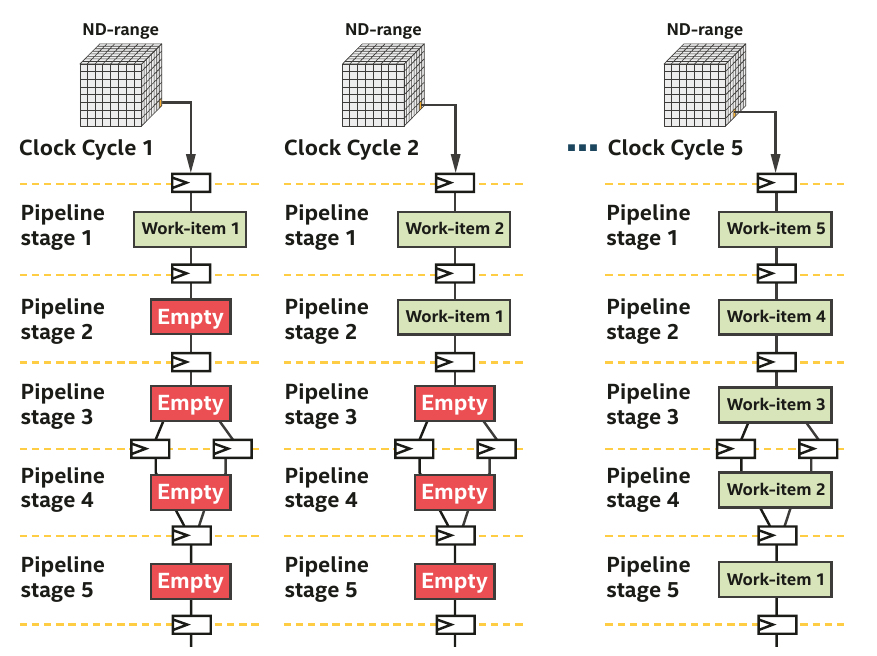
Pipelining with single-work item (loop)¶
- When your code can't be decomposed into independent works, you can rely on loop parallelism using FPGA
- In such a situation, the pipeline inputs is not work-items but loop iterations
- For single-work-item kernels, the developer does not need to do anything special to preserve the data dependency
- Communications between kernels is also much easier
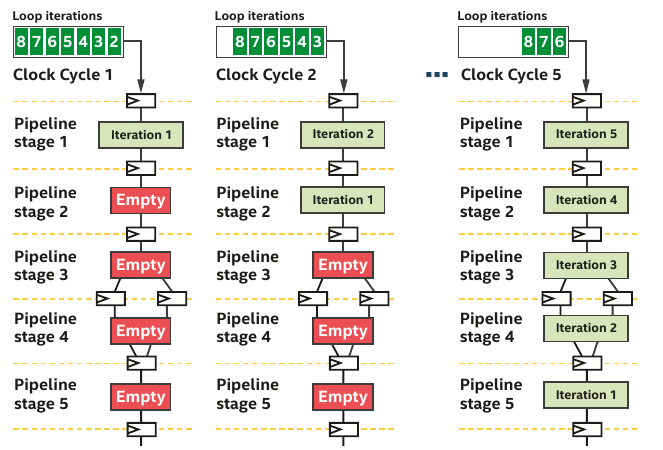
- FPGA can efficiently handle loop execution, often maintaining a fully occupied pipeline or providing reports on what changes are necessary to enhance occupancy.
- It's evident that if loop iterations were substituted with work-items, where the value created by one work-item would have to be transferred to another for incremental computation, the algorithm's description would become far more complex.
MeluXina Bittware 520N-MX FPGAS¶
Each of the 20 MeluXina FPGA compute nodes comprise two BittWare 520N-MX FPGAs based on the Intel Stratix 10 FPGA chip. Designed for compute acceleration, the 520N-MX are PCIe boards featuring Intel’s Stratix 10 MX2100 FPGA with integrated HBM2 memory. The size and speed of HBM2 (16GB at up to 512GB/s) enables acceleration of memory-bound applications. Programming with high abstraction C, C++, and OpenCLis possible through an specialized board support package (BSP) for the Intel OpenCL SDK. For more details see the dedicated BittWare product page.

Intel Stratix 520N-MX Block Diagram.
The Bittware 520N-MX cards have the following specifications:
- FPGA: Intel Stratix 10 MX with MX2100 in an F2597 package, 16GBytes on-chip High Bandwidth Memory (HBM2) DRAM, 410 GB/s (speed grade 2).
- Host interface: x16 Gen3 interface direct to FPGA, connected to PCIe hard IP.
- Board Management Controller
- FPGA configuration and control
- Voltage, current, temperature monitoring
- Low bandwidth BMC-FPGA comms with SPI link
- Development Tools
- Application development: supported design flows - Intel FPGA OpenCL SDK, Intel High-Level Synthesis (C/C++) & Quartus Prime Pro (HDL, Verilog, VHDL, etc.)
- FPGA development BIST - Built-In Self-Test with source code (pinout, gateware, PCIe driver & host test application)
The FPGA cards are not directly connected to the MeluXina ethernet network. The FPGA compute nodes are linked into the high-speed (infiniband) fabric, and the host code can communicate over this network for distributed/parallel applications.
More details on FPGA can be found in the presentation below:
